

 摘要:
Gemma.cpp:在本地高效运行轻量级语言模型 项目概述 Gemma.cpp 是 Google 推出的一个开源项目,旨在将轻量级语言模型 Gemma 高效地运行在本地环境中。该项...
摘要:
Gemma.cpp:在本地高效运行轻量级语言模型 项目概述 Gemma.cpp 是 Google 推出的一个开源项目,旨在将轻量级语言模型 Gemma 高效地运行在本地环境中。该项... 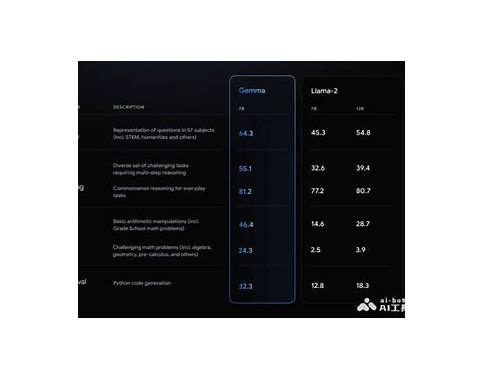
Gemma.cpp:在本地高效运行轻量级语言模型
项目概述
Gemma.cpp 是 Google 推出的一个开源项目,旨在将轻量级语言模型 Gemma 高效地运行在本地环境中。该项目基于流行的 llama.cpp 架构,专门针对 Gemma 模型系列进行了优化,使得用户能够在普通消费级硬件上运行这些先进的自然语言处理模型,而无需依赖云端服务或高性能 GPU。
核心特性
1. 纯 C++ 实现
Gemma.cpp 完全使用 C++ 编写,不依赖复杂的深度学习框架,这使得它具有以下优势: - 部署简单:只需编译即可在各种平台上运行 - 内存效率高:优化的内存管理减少资源消耗 - 运行速度快:针对 CPU 推理进行了专门优化
2. 模型量化支持
项目支持多种量化技术,显著降低模型大小和内存需求: - 4位、5位、8位量化选项 - 保持模型性能的同时大幅减少存储需求 - 支持混合精度推理
3. 跨平台兼容性
- 支持 Windows、Linux、macOS 等主流操作系统
- 兼容 x86 和 ARM 架构
- 可在没有 GPU 的环境中运行
安装与配置
环境要求
- C++17 兼容编译器
- CMake 3.10 或更高版本
- 支持 AVX2 或 ARM NEON 的 CPU(推荐)
编译步骤
text
# 克隆仓库 git clone https://github.com/google/gemma.cpp.git cd gemma.cpp # 创建构建目录 mkdir build && cd build # 配置和编译 cmake .. cmake --build . --config Release
使用示例
1. 基本文本生成
text
#include "gemma.h"
#include <iostream>
int main() {
// 初始化模型配置
gemma::ModelConfig config;
config.model_path = "path/to/gemma-2b-it-q4.bin";
config.tokenizer_path = "path/to/tokenizer.spm";
// 创建模型实例
auto model = gemma::CreateModel(config);
// 设置生成参数
gemma::GenerateConfig gen_config;
gen_config.max_tokens = 100;
gen_config.temperature = 0.7;
// 生成文本
std::string prompt = "解释一下量子计算的基本原理:";
std::string response = model->Generate(prompt, gen_config);
std::cout << "问题:" << prompt << std::endl;
std::cout << "回答:" << response << std::endl;
return 0;
}
2. 对话系统实现
text
#include "gemma.h"
#include <vector>
#include <string>
class ChatBot {
private:
std::unique_ptr<gemma::Model> model_;
std::vector<std::pair<std::string, std::string>> conversation_history_;
public:
ChatBot(const std::string& model_path, const std::string& tokenizer_path) {
gemma::ModelConfig config;
config.model_path = model_path;
config.tokenizer_path = tokenizer_path;
model_ = gemma::CreateModel(config);
}
std::string GenerateResponse(const std::string& user_input) {
// 构建对话上下文
std::string context = BuildConversationContext();
std::string full_prompt = context + "用户:" + user_input + "\n助手:";
// 生成回复
gemma::GenerateConfig gen_config;
gen_config.max_tokens = 150;
gen_config.temperature = 0.8;
std::string response = model_->Generate(full_prompt, gen_config);
// 保存对话历史
conversation_history_.emplace_back(user_input, response);
// 限制历史记录长度
if (conversation_history_.size() > 10) {
conversation_history_.erase(conversation_history_.begin());
}
return response;
}
private:
std::string BuildConversationContext() {
std::string context;
for (const auto& [user, assistant] : conversation_history_) {
context += "用户:" + user + "\n";
context += "助手:" + assistant + "\n";
}
return context;
}
};
3. 批量处理示例
text
#include "gemma.h"
#include <thread>
#include <vector>
void BatchProcessQuestions(const std::vector<std::string>& questions) {
// 初始化模型
gemma::ModelConfig config;
config.model_path = "gemma-2b-it-q4.bin";
auto model = gemma::CreateModel(config);
// 并行处理多个问题
std::vector<std::thread> workers;
std::vector<std::string> answers(questions.size());
for (size_t i = 0; i < questions.size(); ++i) {
workers.emplace_back([&, i]() {
gemma::GenerateConfig gen_config;
gen_config.max_tokens = 200;
gen_config.temperature = 0.6;
answers[i] = model->Generate(questions[i], gen_config);
});
}
// 等待所有线程完成
for (auto& worker : workers) {
if (worker.joinable()) {
worker.join();
}
}
// 输出结果
for (size_t i = 0; i < questions.size(); ++i) {
std::cout << "Q: " << questions[i] << std::endl;
std::cout << "A: " << answers[i] << std::endl;
std::cout << "---" << std::endl;
}
}
性能优化技巧
1. 内存优化
text
// 使用内存池减少分配开销 gemma::ModelConfig config; config.use_memory_pool = true; config.memory_pool_size = 1024 * 1024 * 512; // 512MB // 启用缓存优化 config.enable_kv_cache = true; config.kv_cache_size = 2048;
2. 推理加速
text
// 设置线程数以充分利用多核CPU gemma::GenerateConfig gen_config; gen_config.num_threads = std::thread::hardware_concurrency(); // 调整批处理大小 gen_config.batch_size = 4; // 使用硬件加速指令集 #ifdef __AVX2__ config.use_avx2 = true; #endif
实际应用场景
1. 本地文档分析
text
class DocumentAnalyzer {
public:
std::string SummarizeDocument(const std::string& document) {
std::string prompt = "请总结以下文档的主要内容:\n\n" +
document + "\n\n总结:";
gemma::GenerateConfig config;
config.max_tokens = 100;
config.temperature = 0.3; // 较低温度以获得更确定的输出
return model_->Generate(prompt, config);
}
std::vector<std::string> ExtractKeywords(const std::string& document) {
std::string prompt = "从以下文本中提取5个关键词:\n\n" +
document + "\n\n关键词:";
std::string response = model_->Generate(prompt, {.max_tokens = 50});
// 解析关键词
return ParseKeywords(response);
}
};
2. 代码辅助工具
text
std::string GenerateCode(const std::string& description,
const std::string& language) {
std::string prompt = "用" + language + "编写一个" + description +
"。请只返回代码,不要解释:";
gemma::GenerateConfig config;
config.max_tokens = 300;
config.temperature = 0.2; // 低温度确保代码准确性
return model_->Generate(prompt, config);
}
std::string ExplainCode(const std::string& code) {
std::string prompt = "解释以下代码的功能和工作原理:\n\n```\n" +
code + "\n```\n\n解释:";
return model_->Generate(prompt, {.max_tokens = 200});
}
注意事项和最佳实践
- 模型选择:根据硬件配置选择合适的模型大小和量化版本
- 内存管理:监控内存使用,避免内存泄漏
- 错误处理:实现完善的异常处理机制
- 性能监控:记录推理时间和资源消耗
- 安全考虑:对用户输入进行适当的过滤和验证
总结
Gemma.cpp 为开发者提供了一个高效、便捷的方式来在本地环境中运行先进的语言模型。通过纯 C++ 实现和多种优化技术,它使得在资源受限的环境中部署 AI 应用成为可能。无论是构建聊天机器人、文档分析工具还是代码辅助应用,Gemma.cpp 都提供了一个强大的基础框架。
随着项目的不断发展和优化,我们可以期待它在边缘计算、隐私保护应用和资源受限环境中的更广泛应用。对于需要在本地部署 AI 功能的开发者来说,Gemma.cpp 无疑是一个值得关注和尝试的优秀项目。
gemma.cpp_20260205083201.zip
类型:压缩文件|已下载:0|下载方式:免费下载
立即下载









还没有评论,来说两句吧...