

 摘要:
C++ Whisper.cpp:轻量高效的语音识别引擎 项目概述 Whisper.cpp 是一个基于 OpenAI Whisper 模型的 C++ 实现,专注于提供高效、轻量级的语...
摘要:
C++ Whisper.cpp:轻量高效的语音识别引擎 项目概述 Whisper.cpp 是一个基于 OpenAI Whisper 模型的 C++ 实现,专注于提供高效、轻量级的语... 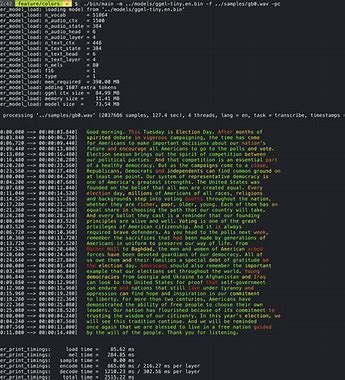
C++ Whisper.cpp:轻量高效的语音识别引擎
项目概述
Whisper.cpp 是一个基于 OpenAI Whisper 模型的 C++ 实现,专注于提供高效、轻量级的语音转文本功能。该项目使用 ggml 张量库进行推理优化,能够在各种硬件平台上运行,特别适合嵌入式设备和资源受限环境。
核心特性
1. 跨平台支持
- 支持 Windows、Linux、macOS 和移动平台
- 无需复杂依赖,易于部署
2. 性能优化
- 使用 ggml 进行模型推理优化
- 支持 CPU 推理,无需 GPU
- 内存占用低,运行效率高
3. 模型支持
- 支持多种 Whisper 模型尺寸(tiny、base、small、medium、large)
- 支持多语言识别
- 可配置的推理参数
安装与使用
基本安装
text
# 克隆项目 git clone https://github.com/ggml-org/whisper.cpp.git cd whisper.cpp # 下载模型(以 base 模型为例) bash ./models/download-ggml-model.sh base # 编译项目 make
基础使用示例
text
// 示例:使用 whisper.cpp 进行语音识别
#include "whisper.h"
int main() {
// 初始化 whisper 上下文
struct whisper_context *ctx = whisper_init_from_file("models/ggml-base.bin");
if (ctx == nullptr) {
fprintf(stderr, "Failed to initialize whisper context\n");
return 1;
}
// 设置参数
struct whisper_full_params params = whisper_full_default_params(WHISPER_SAMPLING_GREEDY);
params.print_realtime = true;
params.print_progress = false;
params.print_timestamps = true;
params.print_special = false;
params.translate = false;
params.language = "en";
params.n_threads = 4;
params.offset_ms = 0;
params.no_context = true;
params.single_segment = false;
// 读取音频文件(需要先转换为 16kHz 16-bit PCM)
std::vector<float> pcmf32 = read_wav("audio.wav", 16000);
// 执行推理
if (whisper_full(ctx, params, pcmf32.data(), pcmf32.size()) != 0) {
fprintf(stderr, "Failed to process audio\n");
return 1;
}
// 获取结果
const int n_segments = whisper_full_n_segments(ctx);
for (int i = 0; i < n_segments; i++) {
const char *text = whisper_full_get_segment_text(ctx, i);
printf("[%d] %s\n", i, text);
}
// 清理资源
whisper_free(ctx);
return 0;
}
命令行工具使用
text
# 基本语音识别 ./main -m models/ggml-base.bin -f audio.wav # 指定语言 ./main -m models/ggml-base.bin -f audio.wav -l zh # 翻译模式(将非英语语音翻译为英语) ./main -m models/ggml-base.bin -f audio.wav --translate # 输出时间戳 ./main -m models/ggml-base.bin -f audio.wav -t 4 -otxt # 实时音频输入 ./main -m models/ggml-base.bin --capture 0
高级功能
1. 流式处理
text
// 流式音频处理示例
void process_streaming_audio(whisper_context* ctx) {
whisper_full_params params = whisper_full_default_params(WHISPER_SAMPLING_GREEDY);
// 分块处理音频
const int chunk_size = 1024;
std::vector<float> audio_buffer;
while (has_more_audio()) {
std::vector<float> chunk = get_next_audio_chunk(chunk_size);
audio_buffer.insert(audio_buffer.end(), chunk.begin(), chunk.end());
// 当缓冲区足够大时进行处理
if (audio_buffer.size() >= 16000 * 30) { // 30秒音频
whisper_full(ctx, params, audio_buffer.data(), audio_buffer.size());
audio_buffer.clear();
}
}
}
2. 自定义回调
text
// 自定义进度回调
void my_new_segment_callback(struct whisper_context* ctx, int n_new, void* user_data) {
printf("New segments: %d\n", n_new);
const int n_segments = whisper_full_n_segments(ctx);
for (int i = n_segments - n_new; i < n_segments; i++) {
const char* text = whisper_full_get_segment_text(ctx, i);
printf("[%d] %s\n", i, text);
}
}
// 使用自定义回调
params.new_segment_callback = my_new_segment_callback;
params.new_segment_callback_user_data = nullptr;
性能优化技巧
1. 线程配置
text
# 根据 CPU 核心数调整线程数 ./main -m models/ggml-base.bin -f audio.wav -t 8
2. 模型选择策略
text
// 根据需求选择合适的模型
enum ModelSize {
TINY = 0, // 最快,精度较低
BASE = 1, // 平衡选择
SMALL = 2, // 较好的精度
MEDIUM = 3, // 高精度
LARGE = 4 // 最高精度,最慢
};
// 根据场景选择模型
ModelSize select_model(bool need_high_accuracy, bool resource_constrained) {
if (resource_constrained) return TINY;
if (need_high_accuracy) return MEDIUM;
return BASE;
}
3. 内存优化
text
// 批量处理多个文件,重用上下文
whisper_context* ctx = whisper_init_from_file("models/ggml-base.bin");
for (const auto& audio_file : audio_files) {
std::vector<float> pcmf32 = read_wav(audio_file, 16000);
whisper_full(ctx, params, pcmf32.data(), pcmf32.size());
// 处理结果...
}
whisper_free(ctx); // 最后统一释放
实际应用场景
1. 嵌入式设备语音助手
text
// 嵌入式设备上的语音命令识别
class VoiceCommandRecognizer {
private:
whisper_context* ctx;
public:
VoiceCommandRecognizer(const std::string& model_path) {
ctx = whisper_init_from_file(model_path.c_str());
}
std::string recognize_command(const std::vector<float>& audio) {
whisper_full(ctx, get_default_params(), audio.data(), audio.size());
const int n_segments = whisper_full_n_segments(ctx);
std::string result;
for (int i = 0; i < n_segments; i++) {
result += whisper_full_get_segment_text(ctx, i);
}
return normalize_command(result);
}
};
2. 实时字幕生成
text
// 实时视频字幕生成系统
class LiveSubtitleGenerator {
public:
void process_audio_frame(const AudioFrame& frame) {
audio_buffer.push_back(frame);
if (audio_buffer.size() >= frame_rate * 5) { // 每5秒处理一次
generate_subtitles();
audio_buffer.clear();
}
}
private:
void generate_subtitles() {
// 使用 whisper.cpp 生成字幕
whisper_full(ctx, params, audio_buffer.data(), audio_buffer.size());
// 格式化并输出字幕
format_and_display_subtitles();
}
};
注意事项
- 音频预处理:确保输入音频为 16kHz、16-bit PCM 格式
- 内存管理:及时释放 whisper_context 避免内存泄漏
- 线程安全:whisper_context 不是线程安全的,需要适当的同步
- 模型选择:根据准确性和性能需求选择合适的模型尺寸
总结
Whisper.cpp 为 C++ 开发者提供了一个强大而高效的语音识别解决方案。其轻量级设计、跨平台支持和优秀的性能表现,使其成为在资源受限环境中部署语音识别功能的理想选择。无论是嵌入式设备、桌面应用还是服务器端处理,Whisper.cpp 都能提供可靠的语音转文本能力。
通过合理的配置和优化,开发者可以在保持高识别准确率的同时,获得出色的运行效率。项目的活跃开发和社区支持也确保了其持续改进和功能增强。
whisper.cpp_20260205143718.zip
类型:压缩文件|已下载:0|下载方式:免费下载
立即下载









还没有评论,来说两句吧...