

 摘要:
引言:音频可视化的工业级解决方案 在数字音频处理领域,波形图的生成是音频编辑器、播客平台以及音乐分析工具中不可或缺的功能。BBC 开源的 audiowaveform 项目正是为此而...
摘要:
引言:音频可视化的工业级解决方案 在数字音频处理领域,波形图的生成是音频编辑器、播客平台以及音乐分析工具中不可或缺的功能。BBC 开源的 audiowaveform 项目正是为此而... 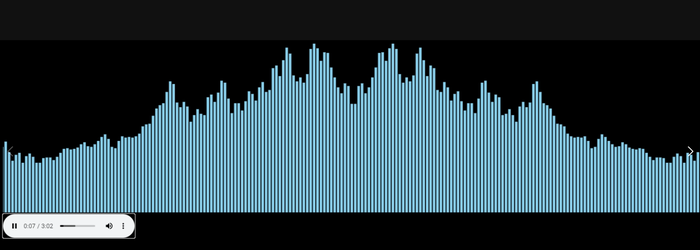
引言:音频可视化的工业级解决方案
在数字音频处理领域,波形图的生成是音频编辑器、播客平台以及音乐分析工具中不可或缺的功能。BBC 开源的 audiowaveform 项目正是为此而生。这是一个基于 C++ 开发的高性能命令行工具及库,能够从各种音频文件中生成高质量的波形图像或 JSON 数据。不同于简单的前端 Canvas 绘制,audiowaveform 在服务器端进行采样计算,能够处理长达数小时的高保真音频文件,且生成的波形数据精确度极高。本文将对该项目进行深入介绍,并提供详细的安装指南与实战实例。
项目核心特性解析
audiowaveform 之所以被 BBC 及其他大型媒体机构广泛采用,主要归功于其以下几个核心特性:
- 多格式支持:支持 MP3、WAV、OGG、FLAC 等多种常见音频格式。这得益于其底层集成了 libmad、libvorbis、libflac 等解码库。
- 双重输出模式:既可以生成 PNG 格式的波形图片,直接用于展示;也可以输出 JSON 数据,供前端 JavaScript 库进行交互式渲染。
- 高度可定制:用户可以精确控制波形的宽度、高度、颜色、采样率以及每像素代表的毫秒数。支持自定义背景色、波形颜色甚至网格线。
- 高性能计算:基于 C++ 编写,利用多核优势,处理大文件时速度远超纯脚本语言实现的方案。
- Zoom 级别控制:允许生成不同 zoom 级别的波形数据,使得前端在缩放时无需重新请求服务器,提升用户体验。
环境依赖与编译安装
由于 audiowaveform 依赖多个第三方库,在编译前需要确保系统环境已准备好相应的开发包。以下以 Ubuntu/Linux 环境为例,说明编译流程。
1. 安装依赖库
在 Debian 或 Ubuntu 系统上,可以通过 apt 包管理器安装必要的开发库:
sudo apt-get install cmake libmad0-dev libvorbis-dev libpng-dev libflac-dev libid3tag0-dev libsox-dev
对于 macOS 用户,可以使用 Homebrew 进行安装:
brew install cmake libmad libvorbis libpng flac libid3tag sox
2. 克隆源码与编译
从 GitHub 获取源代码后,使用 CMake 进行构建。这是标准的 C++ 项目编译流程:
git clone https://github.com/bbc/audiowaveform.git cd audiowaveform mkdir build cd build cmake .. make sudo make install
编译完成后,audiowaveform 可执行文件将被安装到系统路径中,用户可以在任意目录下调用该命令。
命令行实战:生成波形图
安装完毕后,最直接的使用方式是通过命令行工具。以下展示几个典型的使用场景。
基础 PNG 生成
最基础的命令仅需指定输入音频文件和输出图片路径:
audiowaveform -i input.mp3 -o output.png
系统将自动分析音频振幅,并生成默认样式的波形图。默认图片宽度通常较大,适合全屏查看。
定制尺寸与颜色
为了适应不同的展示场景,例如网页缩略图或移动端展示,可以指定图片的宽度和高度,并修改颜色方案:
audiowaveform -i input.mp3 -o output.png \ --width 800 --height 200 \ --background-color "#ffffff" \ --waveform-color "#0000ff" \ --pixels-per-second 100
上述命令中,--pixels-per-second 参数控制了波形的时间密度。数值越大,波形越舒展,细节越丰富;数值越小,越能展示长音频的整体轮廓。
生成 JSON 数据用于前端
在现代 Web 开发中,直接传输图片往往不够灵活。audiowaveform 支持输出 JSON 格式,前端可以使用专门的库(如 wavesurfer.js 的兼容插件)进行渲染。
audiowaveform -i input.mp3 -o output.json --pixels-per-second 100
生成的 JSON 文件包含采样点数据、版本信息以及缩放级别。这种方式大大减少了服务器带宽压力,因为 JSON 文本文件通常比 PNG 图片更小,且前端可以根据容器大小动态绘制。
高级定制与性能优化
在处理专业音频任务时,可能需要更精细的控制。
多通道波形处理
立体声音频包含左右两个声道。audiowaveform 默认会混合声道或分别显示。通过参数 --num-channels,可以强制指定生成的波形是基于单声道还是双声道。对于播客节目,通常单声道波形已足够清晰;对于音乐作品,双声道波形能展示立体声场的动态变化。
大数据量处理策略
当处理长达数小时的录音文件时,全量采样会导致 JSON 文件过大。此时可以利用 --zoom 参数生成多级缩放数据。例如,生成一个包含概览数据和细节数据的复合 JSON 文件。前端在默认视图下只加载概览数据,当用户放大特定区域时,再请求细节数据。虽然 audiowaveform 本身主要生成单一层级数据,但可以通过脚本多次调用不同 pixels-per-second 参数来构建多级数据源。
自动化批处理脚本
在实际生产环境中,往往需要处理成千上万个音频文件。结合 Shell 脚本可以实现自动化流水线:
for file in ./audio_files/*.mp3; do
filename=$(basename "$file" .mp3)
audiowaveform -i "$file" -o "./waveforms/${filename}.png" --width 1200 --height 300
done
此脚本遍历指定目录下的所有 MP3 文件,并为每个文件生成统一规格的波形图,非常适合批量构建媒体库索引。
集成应用案例
播客平台集成
许多播客托管平台利用 audiowaveform 为每个上传的剧集生成预览波形。用户在浏览列表时,无需播放音频,仅通过波形图的起伏即可判断内容的密度和高潮部分。这种视觉反馈显著提升了用户的点击意愿。
音频编辑工具后端
一些轻量级的在线音频剪辑工具,将 audiowaveform 作为后端服务。用户上传音频后,服务器迅速生成波形 JSON 数据返回给前端。前端据此绘制可交互的时间轴,用户通过拖动波形区域来选择剪辑点,最后将剪辑参数发回服务器进行实际处理。这种架构分离了计算密集型任务和交互逻辑,提高了系统稳定性。
常见问题与解决方案
解码错误
如果遇到无法识别的音频格式,通常是因为缺少对应的解码库。例如,处理 M4A 文件可能需要额外的 AAC 解码支持。此时建议先将音频转换为标准的 WAV 或 MP3 格式,再使用 audiowaveform 处理。可以使用 ffmpeg 进行预处理:
ffmpeg -i input.m4a -acodec libmp3lame output.mp3
内存占用过高
处理极长音频文件时,进程可能会占用大量内存。可以通过限制 --width 参数来控制输出图片的像素总量,从而间接控制内存使用。此外,确保服务器拥有足够的 Swap 空间也是一种防御措施。
总结
BBC 的 audiowaveform 项目是音频可视化领域的一颗明珠。它将复杂的音频采样算法封装为简洁的命令行工具,既保留了 C++ 的高性能优势,又提供了灵活的输出选项。无论是需要静态图片的传统媒体,还是追求交互体验的现代 Web 应用,该项目都能提供强有力的支持。通过掌握其编译方法与参数调优,开发者可以轻松为自己的音频产品添加专业的波形展示功能,提升产品的专业度与用户体验。随着音频内容的爆发式增长,高效、精准的波形生成工具将成为基础设施中重要的一环。







还没有评论,来说两句吧...