

 摘要:
问题背景:为什么我们需要“模糊记忆”?从处理数百万交易的银行API,到通过协调自动化生产线的工业平台管理重要患者数据的医院系统。这些系统有一个共同的特点:它们必须每天处理数百万个A...
摘要:
问题背景:为什么我们需要“模糊记忆”?从处理数百万交易的银行API,到通过协调自动化生产线的工业平台管理重要患者数据的医院系统。这些系统有一个共同的特点:它们必须每天处理数百万个A... 问题背景:为什么我们需要“模糊记忆”?
从处理数百万交易的银行API,到通过协调自动化生产线的工业平台管理重要患者数据的医院系统。
这些系统有一个共同的特点:它们必须每天处理数百万个API调用,同时保持出色的性能和可预测的响应时间。
在这种情况下,即使看似简单的操作在扩大业务量时也可能成为关键瓶颈。
一个完美的例子是,在为已经达到1亿用户的社交网络开发用户注册API时,您可以找到什么。
每次有人尝试注册时,您都需要检查电子邮件是否已经存在于数据库中。
看似无辜的咨询SELECT COUNT(*) FROM users WHERE email = ?可能看起来微不足道,但是当在1亿行的表中每分钟执行数千次时,即使使用最好的索引,数据库也开始受到影响。
矛盾的是,这些查询中的绝大多数返回零结果——大多数被验证的电子邮件实际上都是新的。
你实际上是在浪费计算资源,用一种更有效的方法提前确认你可以知道的东西。
这种情况在许多上下文中重复出现:在Web爬虫中已经访问的URL的验证,分布式缓存中的关键字验证,反垃圾邮件过滤器,重复数据删除系统。
检查元素是否“可以存在”的所有成本都远低于最终检查的成本。
原理概述
Bloom Filter由一组位(最初全部为零)和一组哈希函数组成。当你想“记住”一个元素时:
计算元素的几个哈希函数
将这些值用作位数组中的索引
将所有匹配位设置为 1
检查某个元素是否存在:
计算相同的哈希函数
检查所有匹配位是否在 1
如果连一个都在0中,则元素绝对不存在
如果每个人都在1,元素可能就在那里。
美丽且紧凑的:无论你插入多少元素,Bloom过滤器的大小保持不变。
对于我们的1亿封电子邮件,而不是千兆字节的内存,我们只能使用几兆字节,同时保持1%的假阳性概率。
- 用 []uint32 充当位图,节省内存。
- 双重哈希 + 线性组合模拟 k 个独立哈希函数。
以下是Golang实现代码:
package utils
import (
"errors"
"hash/fnv"
"sync"
)
type TBloomFilter struct {
bitArray []uint32 // 位
bitCount uint32 // 总位数
hashFunctions int // 哈希函数个数
mu sync.RWMutex // 读写锁
}
// bitCount:总位数;hashFunctions:哈希函数个数(k)
func NewBloomFilter(bitCount uint32, hashFunctions int) (*TBloomFilter, error) {
if bitCount == 0 {
return nil, errors.New("bit count must be greater than 0")
}
if hashFunctions <= 0 {
return nil, errors.New("hash function count must be greater than 0")
}
// 计算需要多少个 uint32 才能容纳 bitCount 位
size := (bitCount + 31) / 32
return &TBloomFilter{
bitArray: make([]uint32, size),
bitCount: bitCount,
hashFunctions: hashFunctions,
}, nil
}
// bitIndexToSlot 返回位索引对应的槽位(uint32 下标)以及内部位偏移
func (bf *TBloomFilter) bitIndexToSlot(index uint32) (slot uint32, mask uint32) {
slot = index / 32
mask = 1 << (index % 32)
return
}
// setBit 把指定位置 1
func (bf *TBloomFilter) setBit(index uint32) {
slot, mask := bf.bitIndexToSlot(index)
if slot < uint32(len(bf.bitArray)) {
bf.bitArray[slot] |= mask
}
}
// getBit 读取指定位
func (bf *TBloomFilter) getBit(index uint32) bool {
slot, mask := bf.bitIndexToSlot(index)
if slot >= uint32(len(bf.bitArray)) {
return false
}
return bf.bitArray[slot]&mask != 0
}
// computeHash 使用双重哈希+线性组合模拟 k 次哈希
func (bf *TBloomFilter) computeHash(value string, seed uint32) uint32 {
// h1 = FNV-1a
h1 := fnv.New32a()
h1.Write([]byte(value))
hash1 := h1.Sum32()
// h2 = FNV-1a 再写一次 seed 作为扰动
h2 := fnv.New32a()
h2.Write([]byte(value))
h2.Write([]byte{byte(seed), byte(seed >> 8), byte(seed >> 16), byte(seed >> 24)})
hash2 := h2.Sum32()
// 组合公式:(h1 + seed*h2) mod bitCount
combined := uint64(hash1) + uint64(seed)*uint64(hash2)
return uint32(combined % uint64(bf.bitCount))
}
// Add 插入元素
func (bf *TBloomFilter) Add(value string) {
bf.mu.Lock()
defer bf.mu.Unlock()
for i := 0; i < bf.hashFunctions; i++ {
pos := bf.computeHash(value, uint32(i))
bf.setBit(pos)
}
}
// MightContain 判断是否存在
func (bf *TBloomFilter) MightContain(value string) bool {
bf.mu.RLock()
defer bf.mu.RUnlock()
for i := 0; i < bf.hashFunctions; i++ {
pos := bf.computeHash(value, uint32(i))
if !bf.getBit(pos) {
return false
}
}
return true
}
// Clear 重置过滤器
func (bf *TBloomFilter) Clear() {
bf.mu.Lock()
defer bf.mu.Unlock()
for i := range bf.bitArray {
bf.bitArray[i] = 0
}
}
// 计算 BloomFilter 占用的内存字节数(仅位图)
func (bf *TBloomFilter) MemoryUsage() int {
return len(bf.bitArray) * 4
}测试运行
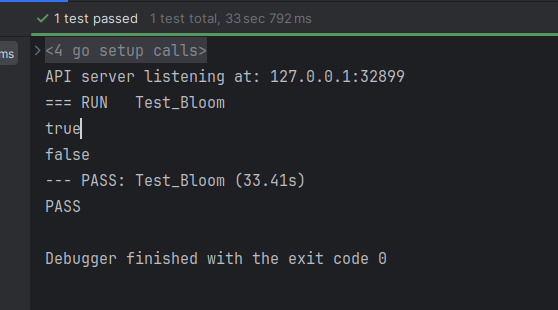
func Test_Bloom(t *testing.T) {
bf, _ := NewBloomFilter(1_000_000, 3)
bf.Add("https://zelig.cn")
fmt.Println(bf.MightContain("https://zelig.cn")) // true
fmt.Println(bf.MightContain("https://baidu.com")) // false(极高概率)
}







还没有评论,来说两句吧...